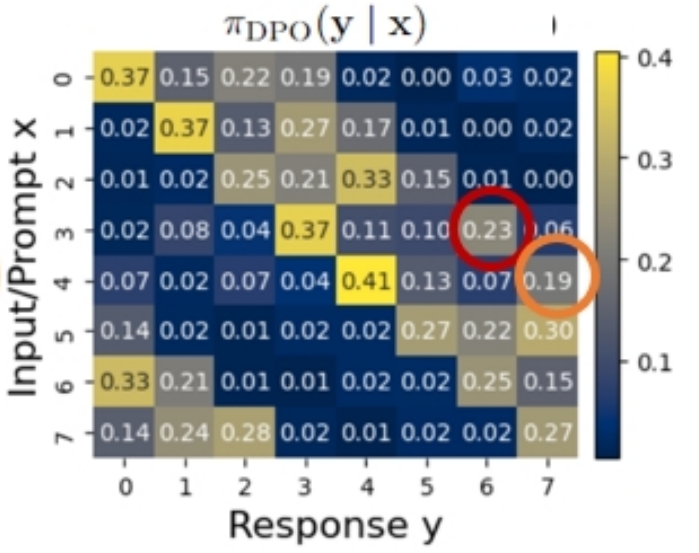
2025 ASearcher Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL Jiaxuan Gao , Wei Fu, Minyang Xie , Shusheng Xu , Chuyi He , Zhiyu Mei , Banghua Zhu , and Yi Wu Aug 2025 PDF Code Website How Far Are We from Optimal Reasoning Efficiency? Jiaxuan Gao , Shu Yan , Qixin Tan , Lu Yang , Shusheng Xu , Wei Fu, Zhiyu Mei , Kaifeng Lyu , and Yi Wu Aug 2025 AReaL AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning Wei Fu, Jiaxuan Gao , Xujie Shen , Chen Zhu , Zhiyu Mei , Chuyi He , Shusheng Xu , Guo Wei , Jun Mei , Jiashu Wang , and 3 more authors May 2025 PDF Code Website ReaLHF ReaL: Efficient RLHF Training of Large Language Models with Parameter Reallocation Zhiyu Mei , Wei Fu, Kaiwei Li , Guangju Wang , Huanchen Zhang , and Yi Wu In MLSys 2025 (*: Equal Contribution) , May 2025 PDF Code Website 2024 On Designing Effective RL Reward at Training Time for LLM Reasoning Jiaxuan Gao , Shusheng Xu , Wenjie Ye , Weilin Liu , Chuyi He , Wei Fu, Zhiyu Mei , Guangju Wang , and Yi Wu May 2024 Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study Shusheng Xu , Wei Fu, Jiaxuan Gao , Wenjie Ye , Weilin Liu , Zhiyu Mei , Guangju Wang , Chao Yu , and Yi Wu ICML. (Oral) , Jul 2024 arXiv SRL SRL: Scaling Distributed Reinforcement Learning to Over Ten Thousand Cores Zhiyu Mei* , Wei Fu*, Guangju Wang , Huanchen Zhang , and Yi Wu ICLR. (*: Equal Contribution) , May 2024 PDF Code Learning Agile Bipedal Motions on a Quadrupedal Robot Yunfei Li , Jinhan Li , Wei Fu, and Yi Wu ICRA, May 2024 arXiv Video Code Website 2023 SIPO Iteratively Learn Diverse Strategies with State Distance Information Wei Fu, Weihua Du* , Jingwei Li* , Sunli Chen , Jingzhao Zhang , and Yi Wu NeurIPS. (*: Equal Contribution) , Dec 2023 arXiv Code Website 2022 Revisiting Some Common Practices in Cooperative Multi-Agent Reinforcement Learning Wei Fu, Chao Yu , Zelai Xu , Jiaqi Yang , and Yi Wu ICML, Jul 2022 arXiv Code Website RSPO Continuously Discovering Novel Strategies via Reward-Switching Policy Optimization Zihan Zhou* , Wei Fu*, Bingliang Zhang , and Yi Wu ICLR. (*: Equal Contribution) , Apr 2022 arXiv Code Website 2021 Unlocking the Potential of MAPPO with Asynchronous Optimization Wei Fu, Chao Yu , Yunfei Li , and Yi Wu In CICAI , Oral , Jun 2021 HTML
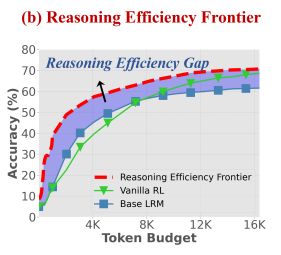 How Far Are We from Optimal Reasoning Efficiency?Aug 2025
How Far Are We from Optimal Reasoning Efficiency?Aug 2025


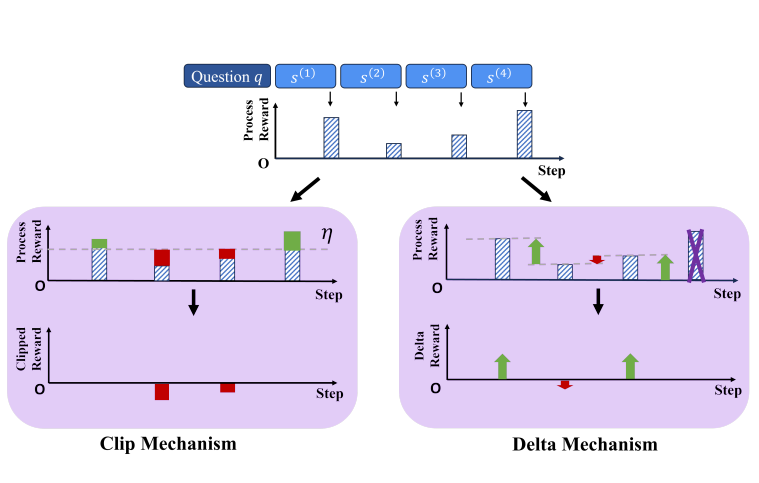 On Designing Effective RL Reward at Training Time for LLM ReasoningMay 2024
On Designing Effective RL Reward at Training Time for LLM ReasoningMay 2024